Reliability first: The costs of digital downtime
In today’s always-on digital economy, information access is the beating heart of global business operations and the expectation is the same: resilience, reliability, and uninterrupted performance.
Reliability is not just an operational preference. It is the defining criteria for modern information management and security strategy. Research shows that IT leaders overwhelmingly prioritise reliability above all other factors when planning new cable networks and data storage provisioning, with 86 percent selecting it as their top decision driver. This places uptime ahead of considerations such as ease of integration and operational simplicity, while only around three percent cite cost as a primary factor in decision making.
This focus reflects a simple truth. Even as industries invests heavily in improved engineering practices, infrastructure efficiencies, and sophisticated monitoring tools, the consequences of digital downtime remains severe. Downtime is not simply inconvenient: it is expensive, disruptive, and in many cases reputationally damaging. As digital infrastructure underpins critical business processes, the tolerance for outages has never been lower.
The economic impact: what downtime really costs
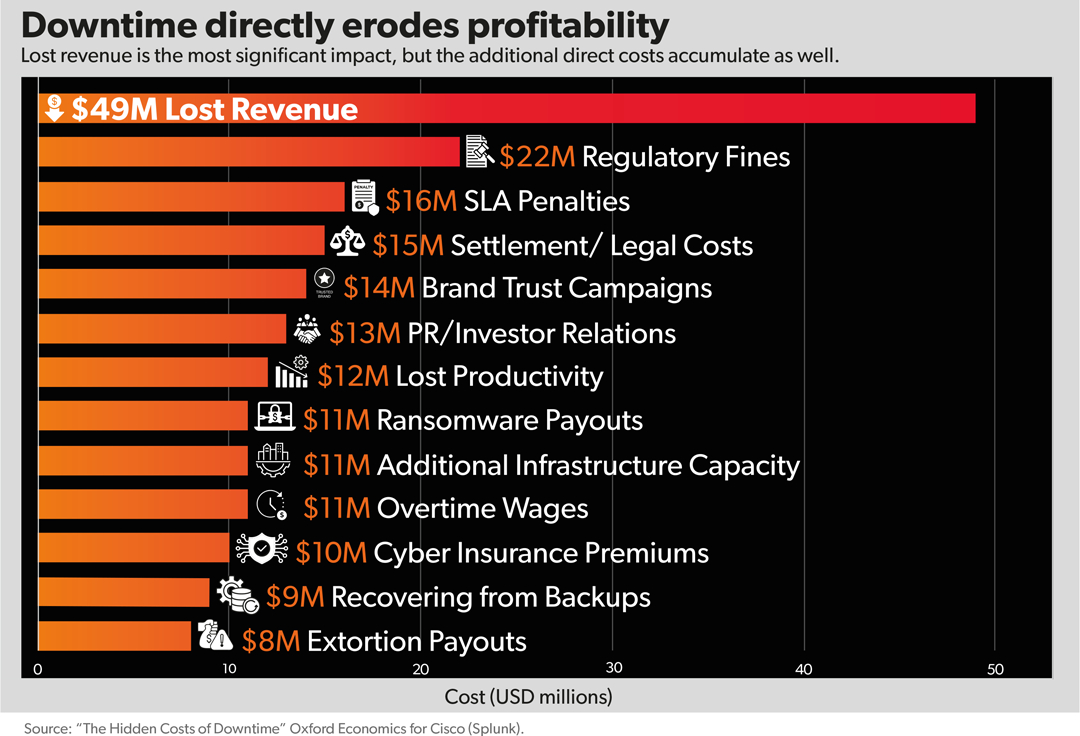
Digital downtime has always carried a cost, but today those costs stack up quickly. A 2024 Oxford Economics study estimated that downtime costs an organisation an average of 9,000 dollars per minute, or a whopping 540,000 dollars for every hour systems are offline. Across Forbes Global 2000 enterprises (a ranking of the largest public companies in the world based on sales, profit, assets and market cap), those minutes accumulate into an estimated impact of around 400 billion dollars each year – a 200-million-dollar average annual loss for each company.
Lost revenue is often the most visible and immediate consequence of a digital outage, but it represents only one part of the financial fallout. Direct costs continue to accumulate long after systems come back online. Organisations absorb expenses linked to SLA penalties, regulatory action, legal and settlement obligations, and operational recovery. Beyond these, longer term costs also begin to surface. Rebuilding customer trust demands sustained effort across brand campaigns, investor communications, and stakeholder reassurance. These activities are not always formally itemised against an outage, yet they are a direct consequence of service disruption and can materially influence overall financial performance.
As digital infrastructure becomes more complex and more deeply embedded in essential services, the consequences of any disruption can escalate quickly, regardless of where the fault originates. Across industry, a clear trend has emerged. Reliability and uptime is the focus. That means the cable infrastructure distributing the power and data has to deliver on both performance and compliance.
Data Centres: The top of the information food chain
At top level, sits a data centre. Whether its on-prem resources, an Edge site, or a hyperscale data centre operate by one of the big tech giants, the principle is the same across the board. Uptime means availability. Power and Data mean connectivity.
When you think of off-prem data centres - whether co-lo, managed sites, or the massive campus sites, there's good news in the fact outages are declining in both frequency and severity, a pattern confirmed across several years of Uptime Institute reporting. This improvement is especially notable given the rapid global growth in data centre capacity.
Data centre availability is typically expressed in percentages, with uptime commitments measured in 99 percent increments. These figures may appear small, but over a full year they translate into very real periods of unplanned downtime. Each additional decimal reflects a significant step up in resilience:
- · 99 percent around 3.65 days
- · 99.9 percent just under 9 hours
- · 99.99 percent under 1 hour
- · 99.999 percent about 5 minutes
Yet the numbers should not invite complacency. Even with fewer major incidents, downtime remains a high impact event. The growing scale and interconnectedness of digital operations mean that when outages occur, they can still disrupt critical services and carry significant financial and operational consequences.
The causes of digital downtime - and mitigating the risk
There is much to consider to maintain information security and information availability. Tracing the root causes of digital downtime shows that outages rarely stem from a single issue. Power‑related faults and cooling failures will feature, particularly as higher rack densities place greater demand on thermal management systems. It can take systems off-line, stop production lines, and bring operations to a halt in an instant.
Cyber-attacks have become another significant source of disruption, with ransomware incidents increasingly able to take critical services offline. Dependencies on third party systems and software can also introduce vulnerabilities, especially where failures or misconfigurations occur upstream of the data centre itself.
External pressures add further complexity. Local grid constraints, severe weather, network provider incidents, and geopolitical instability can all affect availability in ways that you cannot always control.
What you can control is the reliability of the cables that connect your network. Every component matters, every connection plays a significant role. Whether you're installing an office server room or part of a team building a large-scale dark site for multiple tenants, it's about mitigating the risk. That's where Eland Cables plays its role - supplying power and data cables that are tested for quality and compliance by The Cable Lab.
Premature failure, unplanned maintenance, even simple underperformance has to be avoided. When uptime is measured to hundredths of a percent and when downtime can have such wide-ranging costs, reliability really is the word everyone prizes.