Zuverlässigkeit geht vor: die Kosten der Ausfallzeit
In der heutigen, permanent vernetzten digitalen Wirtschaft ist der Informationszugang das Herzstück globaler Geschäftsabläufe, und die Erwartungshaltung ist dieselbe: Widerstandsfähigkeit, Zuverlässigkeit und unterbrechungsfreie Leistung.
Zuverlässigkeit ist nicht nur eine Frage der betrieblichen Präferenz. Es ist das bestimmende Kriterium für moderne Informationsmanagement- und Sicherheitsstrategien. Forschungsergebnisse zeigen, dass IT-Verantwortliche bei der Planung neuer Kabelnetze und der Bereitstellung von Datenspeichern der Zuverlässigkeit mit überwältigender Mehrheit höchste Priorität einräumen – 86 Prozent gaben an, dass dies ihr wichtigster Entscheidungsfaktor sei. Dabei steht die Betriebszeit im Vordergrund, noch vor Aspekten wie der einfachen Integration und der unkomplizierten Bedienung. Nur etwa drei Prozent nennen die Kosten als Hauptfaktor bei der Entscheidungsfindung.
Diese Fokussierung spiegelt eine einfache Wahrheit wider. Auch wenn die Industrie massiv in verbesserte technische Verfahren, effizientere Infrastrukturen und ausgefeilte Überwachungsinstrumente investiert, bleiben die Folgen von digitalen Ausfallzeiten gravierend. Ausfallzeiten sind nicht einfach nur lästig: Sie sind teuer, mit Störungen verbunden und in vielen Fällen rufschädigend. Da die digitale Infrastruktur die Grundlage kritischer Geschäftsprozesse bildet, war die Toleranz gegenüber Ausfällen noch nie so gering.
Die wirtschaftlichen Auswirkungen: Was Ausfallzeiten wirklich kosten
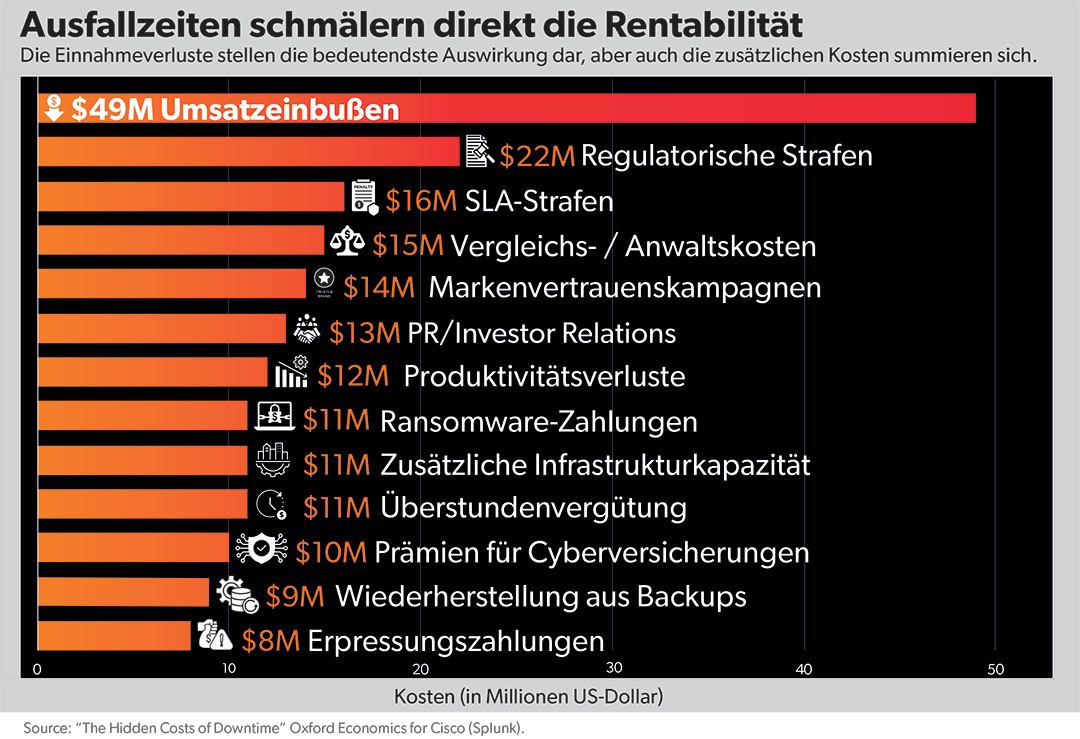
Digitale Ausfallzeiten waren schon immer mit Kosten verbunden, aber heutzutage summieren sich diese Kosten schnell. Eine Studie von Oxford Economics aus dem Jahr 2024 schätzte, dass Ausfallzeiten ein Unternehmen durchschnittlich 9.000 Dollar pro Minute kosten, oder sage und schreibe 540.000 Dollar für jede Stunde, in der Systeme offline sind. Bei den Forbes Global 2000 Unternehmen (ein Ranking der größten börsennotierten Unternehmen der Welt basierend auf Umsatz, Gewinn, Vermögen und Marktkapitalisierung) summieren sich diese Minuten zu einem geschätzten Effekt von rund 400 Milliarden Dollar pro Jahr – ein durchschnittlicher jährlicher Verlust von 200 Millionen Dollar für jedes Unternehmen.
Umsatzeinbußen sind oft die sichtbarste und unmittelbarste Folge eines digitalen Ausfalls, stellen aber nur einen Teil der finanziellen Auswirkungen dar. Die direkten Kosten laufen auch lange nach der Wiederinbetriebnahme der Systeme weiter auf. Organisationen tragen die Kosten im Zusammenhang mit SLA-Strafen, behördlichen Maßnahmen, Rechts- und Vergleichsverpflichtungen sowie der Wiederherstellung des operativen Geschäfts. Darüber hinaus gibt es noch längerfristige Kosten. Die Wiederherstellung des Kundenvertrauens erfordert kontinuierliche Anstrengungen in den Bereichen Markenkampagnen, Investorenkommunikation und Beruhigung der Interessengruppen. Diese Aktivitäten werden nicht immer formell einer Störung zugeordnet, sind aber eine direkte Folge der Serviceunterbrechung und können die finanzielle Gesamtleistung erheblich beeinflussen.
Da die digitale Infrastruktur immer komplexer wird und immer stärker in essentielle Dienste integriert ist, können sich die Folgen einer Störung schnell verschärfen, unabhängig davon, wo die Störung ihren Ursprung hat. Branchenübergreifend hat sich ein klarer Trend herausgebildet. Zuverlässigkeit und Verfügbarkeit stehen im Fokus. Das bedeutet, dass die Kabelinfrastruktur, die Strom und Daten verteilt, sowohl Leistung als auch Konformität gewährleisten muss.
Rechenzentren: Die Spitze der Informationsnahrungskette
Auf oberster Ebene befindet sich ein Rechenzentrum. Ob es sich um On-Premise-Ressourcen, einen Edge-Standort oder ein von einem der großen Technologiekonzerne betriebenes Hyperscale-Rechenzentrum handelt, das Prinzip ist überall dasselbe. Betriebszeit bedeutet Verfügbarkeit. Strom und Daten bedeuten Vernetzung.
Wenn man an externe Rechenzentren denkt – seien es Colocation-Standorte, Managed Sites oder die massiven Campus-Standorte – gibt es eine gute Nachricht: Ausfälle nehmen sowohl in ihrer Häufigkeit als auch in ihrer Schwere ab. Dieses Muster wird durch die mehrjährige Berichterstattung des Uptime Institute bestätigt. Diese Verbesserung ist besonders bemerkenswert angesichts des rasanten globalen Wachstums der Rechenzentrumskapazität.
Die Verfügbarkeit von Rechenzentren wird typischerweise in Prozent angegeben, wobei die Verfügbarkeitszusagen in 99-Prozent-Schritten gemessen werden. Diese Zahlen mögen gering erscheinen, aber auf ein gesamtes Jahr hochgerechnet bedeuten sie reale Zeiträume ungeplanter Ausfallzeiten. Jede zusätzliche Dezimalstelle spiegelt einen signifikanten Anstieg der Widerstandsfähigkeit wider:
- 99 Prozent: etwa 3,65 Tage
- 99.9 Prozent: knapp unter 9 Stunden
- 99.99 Prozent: unter einer Stunde
- 99.999 Prozent: ca. 5 Minuten
Doch die Zahlen sollten nicht zu Selbstzufriedenheit verleiten. Auch bei weniger schwerwiegenden Zwischenfällen bleibt die Ausfallzeit ein Ereignis mit erheblichen Auswirkungen. Die zunehmende Größe und Vernetzung digitaler Systeme bedeutet, dass Ausfälle immer noch kritische Dienste beeinträchtigen und erhebliche finanzielle und betriebliche Folgen nach sich ziehen können.
Die Ursachen digitaler Ausfallzeiten – und wie sich das Risiko mindern lässt
Es gibt vieles zu beachten, um die Informationssicherheit und die Verfügbarkeit von Informationen zu gewährleisten. Die Untersuchung der eigentlichen Ursachen digitaler Ausfallzeiten zeigt, dass diese selten auf ein einziges Problem zurückzuführen sind. Strombedingte Störungen und Kühlungsausfälle werden zunehmen, insbesondere da höhere Rack-Dichten größere Anforderungen an die Thermomanagementsysteme stellen. Es kann Systeme offline nehmen, Produktionslinien stoppen und den Betrieb im Handumdrehen zum Erliegen bringen.
Cyberangriffe haben sich zu einer weiteren bedeutenden Störungsquelle entwickelt, wobei Ransomware-Vorfälle zunehmend in der Lage sind, kritische Dienste offline zu nehmen. Abhängigkeiten von Systemen und Software Dritter können ebenfalls Sicherheitslücken verursachen, insbesondere wenn Fehler oder Fehlkonfigurationen vor dem Rechenzentrum selbst auftreten.
Äußere Einflüsse erhöhen die Komplexität zusätzlich. Lokale Netzengpässe, extreme Wetterereignisse, Störungen bei Netzbetreibern und geopolitische Instabilität können die Verfügbarkeit auf eine Weise beeinträchtigen, die Sie nicht immer kontrollieren können.
Was Sie kontrollieren können, ist die Zuverlässigkeit der Kabel, die Ihr Netzwerk verbinden. Jede Komponente zählt, jede Verbindung spielt eine wichtige Rolle. Ganz gleich, ob Sie einen Büro-Serverraum installieren oder Teil eines Teams sind, das einen großflächigen Dark-Site-Standort für mehrere Mieter errichtet – es geht immer darum, das Risiko zu mindern. Hier kommt Eland Cables ins Spiel – das Unternehmen liefert Strom- und Datenkabel, die von The Cable Lab auf Qualität und Konformität geprüft werden.
Vorzeitige Ausfälle, ungeplante Wartungsarbeiten und selbst einfache Minderleistung müssen vermieden werden. Wenn die Verfügbarkeit bis auf Hundertstelprozente gemessen wird und Ausfallzeiten derart weitreichende Kosten verursachen können, ist Zuverlässigkeit tatsächlich der Wert, den jeder am höchsten schätzt.